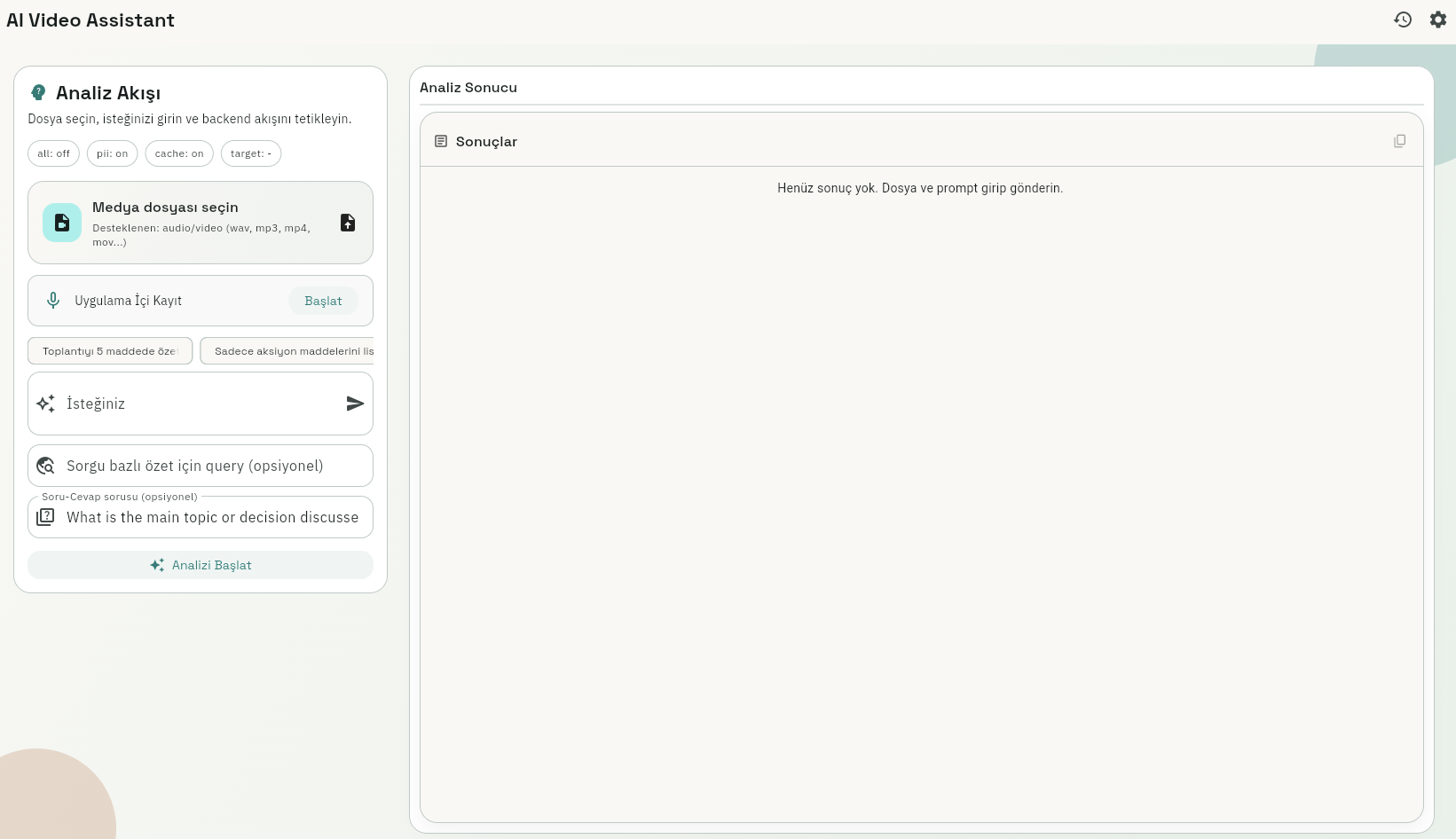
Whisper-Based Speech & NLP System
Built a server-side speech and text pipeline around Whisper transcription, prompt-based summarization, and Hugging Face model integration.
Languages
TR / EN
Speech support
Pipeline
STT + NLP
Audio to text insights
Deploy
Self-hosted
Server-side focus
Project Gallery

1/2
Problem
Speech workflows often depend on external SaaS layers, making local experimentation, privacy-aware deployment, and custom text processing harder.
Challenge
The system had to support Turkish and English inputs while keeping transcription, summarization, and downstream NLP steps modular.
Architecture
How the pieces fit together.
Audio enters a Whisper transcription stage, passes into language-aware text normalization, then flows into prompt-based summarization and optional model adapters.
Architecture View
System structure and decision flow
Audio Input
Turkish and English speech files.
Whisper STT
Server-side transcription and normalization.
NLP Layer
Prompt summarization and Hugging Face adapters.
Dataset / Inputs
- Turkish and English audio inputs with downstream text processing requirements for summarization and analysis.
Technical Decisions
- Keep transcription, normalization, summarization, and model adapters modular.
- Treat deployment constraints as part of the pipeline design.
- Support prompt templates for repeatable NLP outputs.
Implementation Details
- Whisper handles speech-to-text on the server side.
- Text is normalized before prompt-based summarization.
- Hugging Face adapters can be attached for task-specific NLP processing.
Metrics / Results
- The pipeline creates a foundation for local/server-side speech-to-text workflows with extensible NLP post-processing.
Lessons Learned
- Speech-to-text quality is only one part of the user-facing workflow.
- Language-aware cleanup improves downstream model behavior.
- Self-hosting makes observability and customization easier.
Future Improvements
- Add diarization for multi-speaker audio.
- Introduce async job queues for long transcriptions.
- Store transcript versions and prompt outputs for review.